
Claude Sonnet
Différentes version de Claude Sonnet :
Journaux liées à cette note :
J'ai découvert MimiMax M2.7, qui semble équivalent à GLM-5 pour un tiers du prix
#JaiDécouvert la sortie de MiniMax M2.7 le 18 mars 2026 : https://www.minimax.io/news/minimax-m27-en.
Pour donner du contexte, j'utilise depuis le 12 mars 2026 les modèles GLM-5, Kimi K2.5 et MiniMax M2.5 via l'offre OpenCode Go. Je n'ai pas comparé rigoureusement ces modèles avec Sonnet 4.6 et Opus 4.6, mais pour le moment, je suis satisfait de ces modèles. J'ai même l'impression que MiniMax M2.5, le moins cher, suffit pour la majorité de mes besoins.
J'ai lu l'article "MiniMax M2.7 Review: Is It Worth the Hype?", mais c'est finalement MiniMax M2.7: Everything you need to know qui m'a été le plus utile, voici sa traduction :
MiniMax a publié MiniMax-M2.7, offrant une intelligence de niveau GLM-5 pour moins d'un tiers du coût
MiniMax-M2.7 de @MiniMax_AI obtient un score de 50 sur l'Artificial Analysis Intelligence Index, une amélioration de 8 points par rapport à MiniMax-M2.5, publié il y a un mois. Cette amélioration est portée par une performance améliorée sur les tâches agentiques du monde réel et une réduction des hallucinations. MiniMax-M2.7 est désormais devant MiMo-V2-Pro (Reasoning, 49) et Kimi K2.5 (Reasoning, 47), et équivalent à GLM-5 (Reasoning, 50) tout en utilisant 20% de tokens de sortie en moins et coûtant moins d'un tiers du prix pour fonctionner. MiniMax-M2.7 est un modèle uniquement raisonnement et maintient le même prix par token que MiniMax-M2.5.
Points clés :
➤ Performance solide sur les tâches agentiques du monde réel : MiniMax-M2.7 atteint un Elo GDPval-AA de 1494, une amélioration significative par rapport à MiniMax-M2.5 (1203) et devant MiMo-V2-Pro (Reasoning, 1426), GLM-5 (Reasoning, 1406) et Kimi K2.5 (Reasoning, 1283). Il reste derrière les modèles de pointe tels que GPT-5.4 (xhigh, 1667) et Claude Opus 4.6 (Adaptive Reasoning, max effort, 1606).
- Réduction des hallucinations : MiniMax-M2.7 obtient un score de +1 sur l'AA-Omniscience Index, contre -40 pour MiniMax-M2.5. Cela le place en compétition avec GPT-5.2 (xhigh, -1) et GLM-5 (Reasoning, +2), et bien devant Kimi K2.5 (Reasoning, -8). L'amélioration par rapport à M2.5 est entièrement due à la réduction des hallucinations, ce qui signifie que le modèle est plus susceptible de s'abstenir de répondre lorsqu'il ne connaît pas la réponse, plutôt que de deviner. M2.7 atteint un taux d'hallucination de 34%, inférieur à Claude Sonnet 4.6 (Adaptive Reasoning, max effort, 46%) et Gemini 3.1 Pro Preview (50%).
- Gains sur la plupart des évaluations par rapport à MiniMax-M2.5 : En dehors des améliorations du GDPval-AA et de l'AA-Omniscience notées ci-dessus, MiniMax-M2.7 progresse en HLE (+9 p.p.), TerminalBench Hard (+5 p.p.), SciCode (+4 p.p.), IFBench (+4 p.p.), GPQA (+3 p.p.) et LCR (+3 p.p.). Nous avons constaté une régression notable en τ²-Bench (-11 p.p.).>
- Utilisation accrue de tokens : MiniMax-M2.7 a utilisé environ 87M tokens de sortie pour exécuter l'Artificial Analysis Intelligence Index, en hausse de 55% par rapport à MiniMax-M2.5 (environ 56M). Il reste plus efficace en tokens que d'autres modèles tels que GLM-5 (Reasoning, 110M) et Kimi K2.5 (Reasoning, environ 89M).
- Rentabilité de pointe : MiniMax-M2.7 a coûté 176 $ pour exécuter l'Artificial Analysis Intelligence Index, maintenant le même prix de 0,30 $/1,20 $ par million de tokens d'entrée/sortie que M2.5. Cela le place sur la frontière de Pareto de notre graphique Intelligence vs. Coût. À titre de référence, GLM-5 (Reasoning) a coûté 547 $ à intelligence équivalente, Kimi K2.5 (Reasoning) 371 $, et Gemini 3 Flash Preview (Reasoning) 278 $.
Détails clés du modèle :
- Fenêtre de contexte : 200K tokens (équivalent à MiniMax-M2.5).
- Tarification : 0,30 $/1,20 $ par million de tokens d'entrée/sortie (inchangé par rapport à MiniMax-M2.5).
- Disponibilité : API propriétaire MiniMax uniquement.
- Modalité : Entrée et sortie de texte uniquement (pas de multimodalité).
- Licence : MiniMax n'a pas annoncé si MiniMax-M2.7 sera en open weights. MiniMax-M2.5 est disponible sous licence MIT.
MiniMax M2.7 a été intégré dans l'offre OpenCode Go, par conséquent, je vais tester ce modèle dans mes projets OpenCode.
Cette note est la suite de la note "J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR" :
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour
stephane-klein/fedora-rpm-copr-playgroundpour les tester et ensuite publier une nouvelle note de compte rendu.
Voici ce que Claude Sonnet 4.6 m'a appris au sujet des méthodes Tito et Packit :
Tito (~2008) est issu de l'équipe Red Hat Network / Spacewalk. C'est un outil local de gestion du cycle de vie RPM : il gère le tagging Git (
tito tag), incrémente la version dans le.spec, génère automatiquement les changelogs depuis l'historique Git et produit des SRPMs. Ce sont des opérations que le développeur invoque manuellement sur sa workstation, avant de committer et pousser son travail.Packit (~2019) est un projet Red Hat conçu pour l'ère CI/CD GitHub/GitLab. Son rôle est d'orchestrer automatiquement les builds RPM (via COPR), et optionnellement les soumissions Koji et les updates Bodhi pour les projets intégrés à la distribution officielle Fedora, en réaction à des événements upstream (push, PR, release, ou création d'un tag). Il peut également mettre à jour le changelog à partir des commits, mais cette opération intervient au moment où il prépare la mise à jour vers le dist-git Fedora — non pas comme étape explicite du workflow local du développeur.
La différence fondamentale entre les deux n'est donc pas tant dans quand le build est déclenché — les deux peuvent travailler sur tag — que dans comment le workflow de tagging est géré : avec Tito, c'est le développeur qui crée le tag depuis sa workstation, alors que Packit suppose que le tag existe déjà et déclenche automatiquement le build sur l'infrastructure Fedora (Copr, Koji ou Bodhi selon la configuration) à sa création ou à tout autre événement upstream configuré.
Les deux sont des projets Red Hat gravitant autour de l'écosystème Fedora/RPM, sans que l'un soit le successeur de l'autre. Tito lui-même recommande aujourd'hui Packit pour automatiser les Bodhi updates. Beaucoup de projets Fedora les utilisent d'ailleurs conjointement : Tito pour gérer le versioning et le tagging en local, Packit pour automatiser la distribution en aval.
J'ai intégré Packit à fedora-rpm-copr-playground, dans la branche bash-packit.
Avant de pouvoir utiliser Packit pour build un package RPM d'un projet qui se trouve dans un repository GitHub, il est nécessaire de suivre un certain nombre d'étapes détaillées dans le "Packit Upstream Onboarding Guide" :
- Activer l'application GitHub nommée "Packit-as-a-Service" : https://packit.dev/docs/guide/#github
- Ensuite suivre l'étape "Approval" — j'ai perdu du temps dans le playground parce que j'étais totalement passé à côté de cette étape : https://packit.dev/docs/guide/#2-approval
Voici l'issue GitHub qui a permis l'approbation de mon compte : https://github.com/packit/notifications/issues/716 - Créer un projet COPR et ajouter des permissions "admin" à "packit" (voir ligne 18).
J'ai automatisé cette étape avec le script
/init-copr-project.sh.
Ensuite, j'ai intégré le fichier /.packit.yaml à la racine de mon playground, avec le contenu suivant :
specfile_path: rpm/hello-bash.spec
upstream_package_name: hello-bash
downstream_package_name: hello-bash
upstream_tag_template: "v{version}"
actions:
create-archive:
- bash rpm/create-archive.sh
jobs:
- job: copr_build
trigger: release
owner: stephaneklein
project: hello-bash-packit
targets:
- fedora-42
- fedora-43
- fedora-44
preserve_project: true
Je ne vais pas détailler ici le contenu de ce fichier, je vous renvoie vers la documentation officielle :
La configuration trigger: release dans .packit.yaml signifie qu'il faut créer une release GitHub pour obtenir un package. Pour cela j'utilise de script /release.sh qui exécute :
gh release create "$VERSION" --title "Release $VERSION" --generate-notes
Une fois la commande suivante exécutée :
$ ./release.sh v1.0.15
L'exécution du job de génération du package SRPM est visible sur le backend Packit à cette adresse : https://dashboard.packit.dev/jobs/srpm
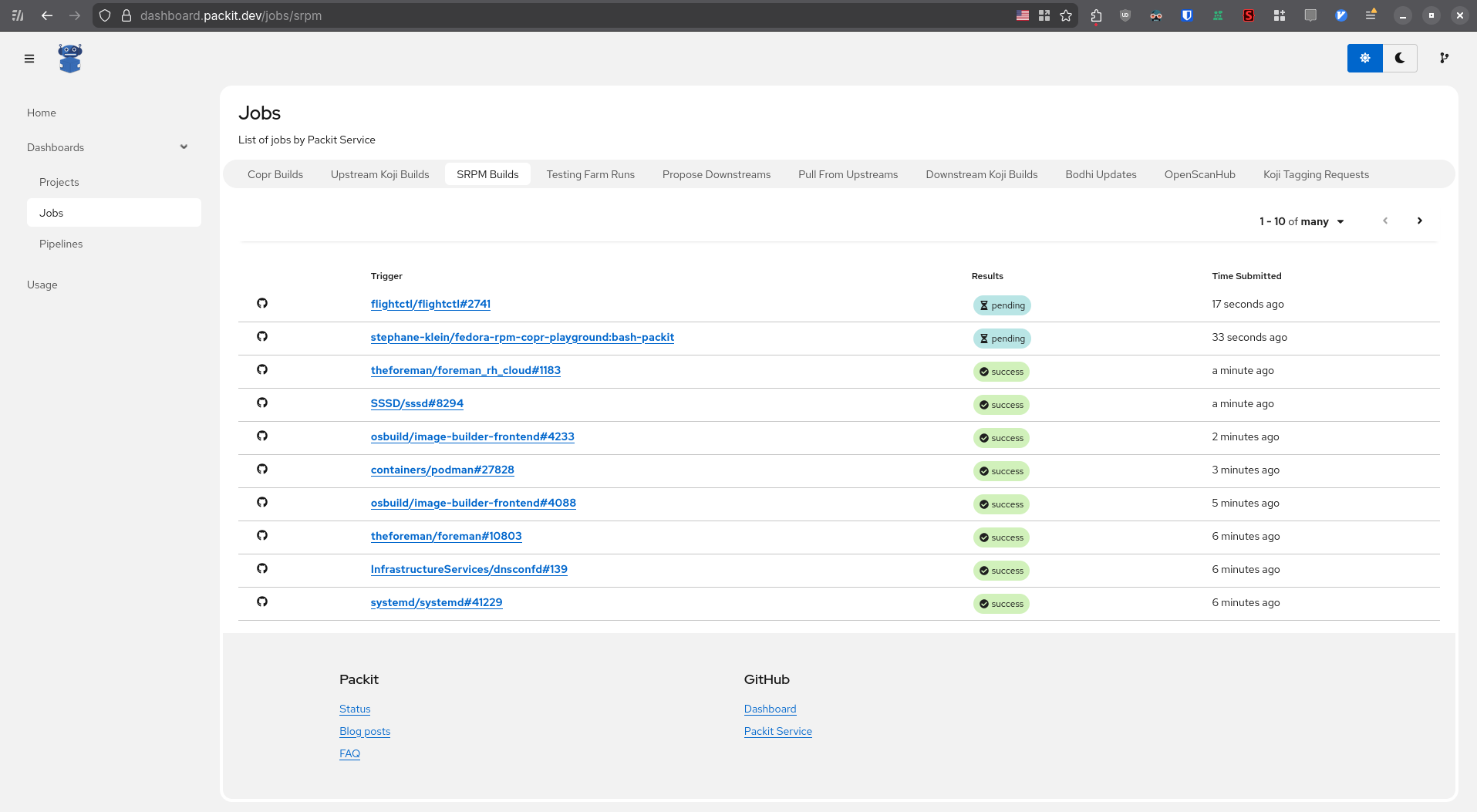
Une fois ce job terminé, c'est ensuite le backend COPR qui s'occupe de construire les packages RPM pour toutes les distributions indiquées dans le fichier .packit.yaml :
En conclusion, j'ai réussi à configurer Packit pour construire mes packages RPM. Cependant, la configuration est plus complexe que la méthode make_srpm. Selon moi, Packit est à utiliser pour les packages destinés à être intégrés officiellement à Fedora, tandis que make_srpm convient mieux pour les autres.
J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR
Introduction
Après trois ans à repousser ce projet, je me suis enfin lancé en janvier 2026 dans la création de paquets RPM pour Fedora COPR.
J'ai créé et publié les packages aichat-git (repository) et text-to-audio (repository). L'expérience a été beaucoup plus simple et rapide que je le pensais. Les agents IA simplifient certes ce genre de tâche, mais même sans eux, le code reste plutôt minimaliste.
Pourquoi est-ce que je me suis intéressé à ce sujet ? Au départ, c'était pour distribuer qemu-compose sous forme de package RPM (voir issue).
Pour bien maîtriser ces opérations, la semaine dernière, je suis reparti de zéro et j'ai implémenté et publié le playground : fedora-rpm-copr-playground. Voici les objectifs de ce playground :
- Générer un package pour distribuer un simple script Bash qui affiche un "Hello world" (dans la branche
bash). - Générer un package pour distribuer une application Golang qui affiche un "Hello world" (dans la branche
golang)
Pour chacun de ces packages, j'ai testé trois méthodes de build :
- build du package RPM 100% local
- build du package SRPM en local, puis upload sur Fedora COPR qui génère les RPM pour plusieurs plateformes et architectures (x86_64, aarch64, etc.)
- une méthode basée à 100% sur Fedora COPR à partir des sources d'un dépôt GitHub, déclenchée automatiquement par un script GitHub Actions
Cette note documente ce playground et rassemble les difficultés que j'ai rencontrées. Le README.md reste consultable si vous préférez suivre un exemple pas à pas.
Le fichier .spec
Le point central pour créer un package RPM est le fichier .spec /rpm/hello-bash.spec :
#
Name: hello-bash
Version: 1.0.7
Release: 1%{?dist}
Summary: A simple Hello World bash script
License: MIT
URL: https://github.com/stephane-klein/fedora-rpm-copr-playground
Source0: hello-bash
BuildArch: noarch
%description
A simple "Hello World" Bash script packaged as an RPM for Fedora COPR.
%prep
# Nothing to prepare, source is ready
%build
# Nothing to build, it's a bash script
%install
mkdir -p %{buildroot}/%{_bindir}
cp %{SOURCE0} %{buildroot}/%{_bindir}/hello-bash
chmod 755 %{buildroot}/%{_bindir}/hello-bash
%files
%{_bindir}/hello-bash
%changelog
* Thu Mar 19 2026 Stéphane Klein <contact@stephane-klein.info> - 1.0.0-1
- Initial release
Les lignes importantes dans ce fichier :
BuildArch: noarch, étant donnée que c'est un simple script, ce package n'est pas dépendant de l'architecture (processeur).- La section
%install - La section
%files
La syntaxe du format .spec peut sembler étrange en 2026. Elle date de 1995 — avant même l'existence de YAML (2001) et JSON (1999). Cette ancienneté explique les %... et %{...} qui peuvent paraitre cryptiques aujourd'hui.
Historiquement, le champ Source0 pointe vers une archive (généralement un tar.gz), contenant les sources du projet. Pour des cas simples, comme ici avec le script Bash, Source0 peut directement référencer le fichier source.
J'ai aussi implémenté une variante bash-multifiles dans le playground, pour tester le packaging de plusieurs scripts accompagnés d'un fichier de documentation. J'y indique les fichiers via Source0:, Source1:, Source2:, puis je les copie dans %install avec %{SOURCE0}, %{SOURCE1}, %{SOURCE2}. Cela fonctionne correctement, bien qu'au-delà de trois ou quatre fichiers, je pense qu'il soit probablement plus pratique d'utiliser une archive.
Build local du package RPM
Le script /build.sh suivant permet de générer un package RPM :
#!/bin/bash
set -e
TOPDIR="$(pwd)/rpmbuild"
mkdir -p "$TOPDIR"/{BUILD,RPMS,SRPMS,SOURCES,SPECS}
echo "Copying source to SOURCES..."
cp hello-bash "$TOPDIR/SOURCES/"
echo "Building RPM..."
rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-bash.spec
echo ""
echo "Build complete!"
echo "RPM: $TOPDIR/RPMS/noarch/"
Il commence par préparer la structure de dossier suivante :
/rpmbuild/
├── BUILD
├── RPMS
├── SOURCES
├── SPECS
└── SRPMS
Ensuite les fichiers à packager sont copiés dans rpmbuild/SOURCES
/rpmbuild/
├── BUILD
├── RPMS
├── SOURCES
│ ├── hello-bash
├── SPECS
└── SRPMS
Pour finir, la commande rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-bash.spec génère à la fois le package SRPM (source RPM) et le RPM binaire. L'option -ba signifie "build all". Pour générer uniquement le SRPM, il faudrait utiliser -bs (build source). Ici, comme le package contient un script Bash, il est de type noarch :
/rpmbuild/
├── BUILD
├── RPMS
│ └── noarch
│ └── hello-bash-1.0.7-1.fc42.noarch.rpm
├── SOURCES
│ ├── hello-bash
├── SPECS
└── SRPMS
└── hello-bash-1.0.7-1.fc42.src.rpm
Publication sur Fedora COPR
Le playground contient un second script qui permet de publier le package sur Fedora COPR, ce qui permet de rendre accessible publiquement son package.
Voici comment cette méthode fonctionne. Tout d'abord, il faut créer un compte et un projet sur Fedora COPR. Dans le playground, j'ai implémenté le script init-copr-project.sh basé sur copr-cli, qui me permet d'automatiser la création du projet (paradigme GitOps).
$ copr-cli create "hello-bash" \
--description "A simple Hello World Bash script packaged as an RPM (auto-build on tags)" \
--chroot fedora-42-x86_64 \
--chroot fedora-43-x86_64 \
--chroot fedora-44-x86_64
Dans cet exemple, je demande à COPR de builder les packages du projet pour les distributions fedora-42-x86_64, fedora-43-x86_64, fedora-44-x86_64.
Après avoir configuré le projet COPR, je lance le script /build-copr.sh qui exécute :
copr-cli build "hello-bash" /rpmbuild/SRPMS/hello-bash-1.0.6-1.fc42.src.rpm
Le premier paramètre "hello-bash" est le nom du projet et le second est le package source SRPM préalablement construit localement par le script /build.sh.
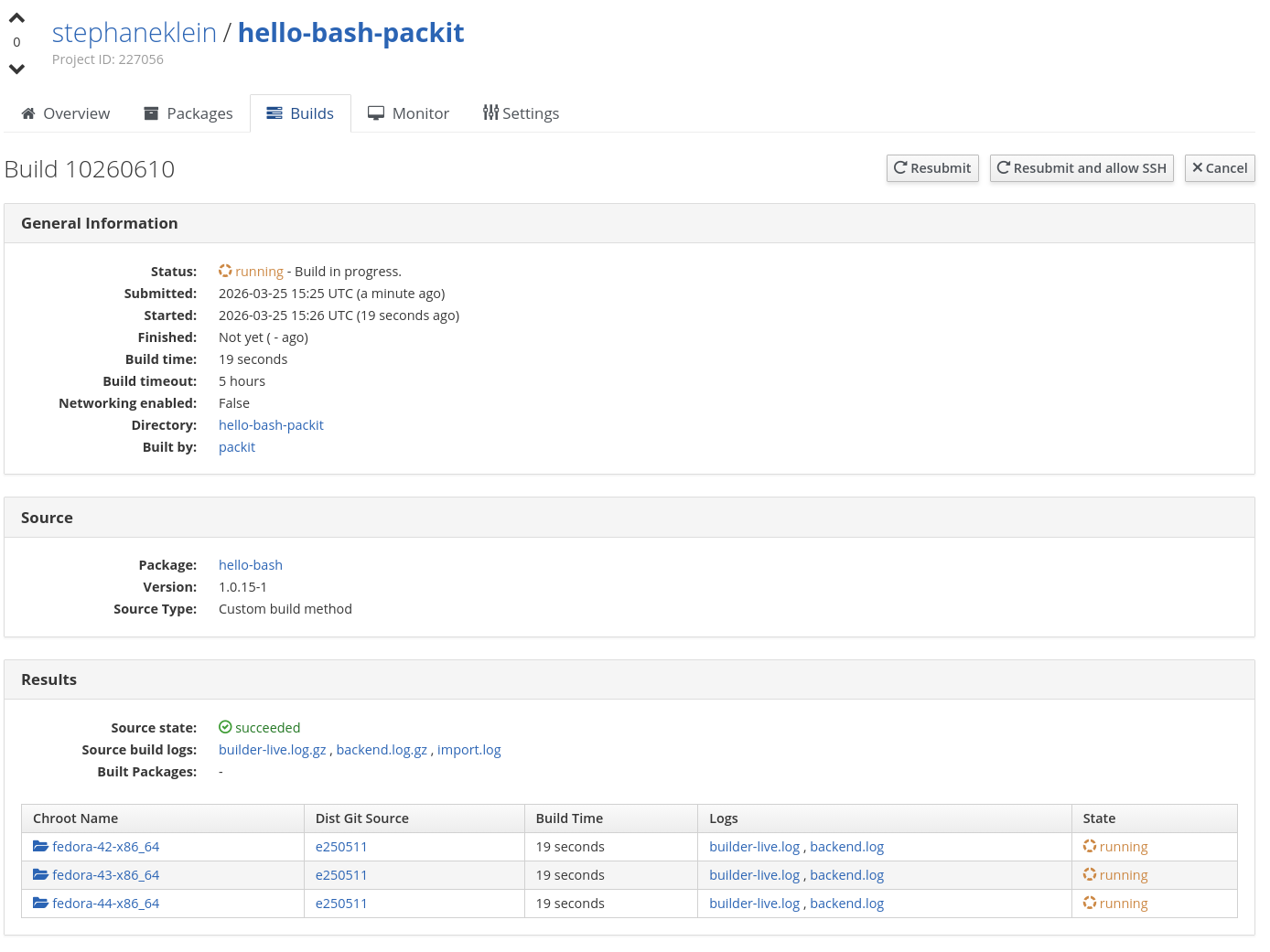
Voici ce que donne l'exécution de ./build-copr.sh côté cli :
$ ./build-copr.sh
...
Build complete!
RPM: /home/stephane/git/github.com/stephane-klein/fedora-rpm-copr-playground/.worktree/bash/rpmbuild/RPMS/noarch/
Uploading package ./rpmbuild/SRPMS/hello-bash-1.0.6-1.fc42.src.rpm
|################################| 8.5 kB 47.1 kB/s eta 0:00:00
Build was added to hello-bash:
https://copr.fedorainfracloud.org/coprs/build/10252699
Created builds: 10252699
Watching build(s): (this may be safely interrupted)
08:59:15 Build 10252699: pending
08:59:45 Build 10252699: running
09:00:15 Build 10252699: starting
09:00:46 Build 10252699: running
Voici ce qui est visible sur l'interface web de COPR, https://copr.fedorainfracloud.org/coprs/stephaneklein/hello-bash/builds/ :
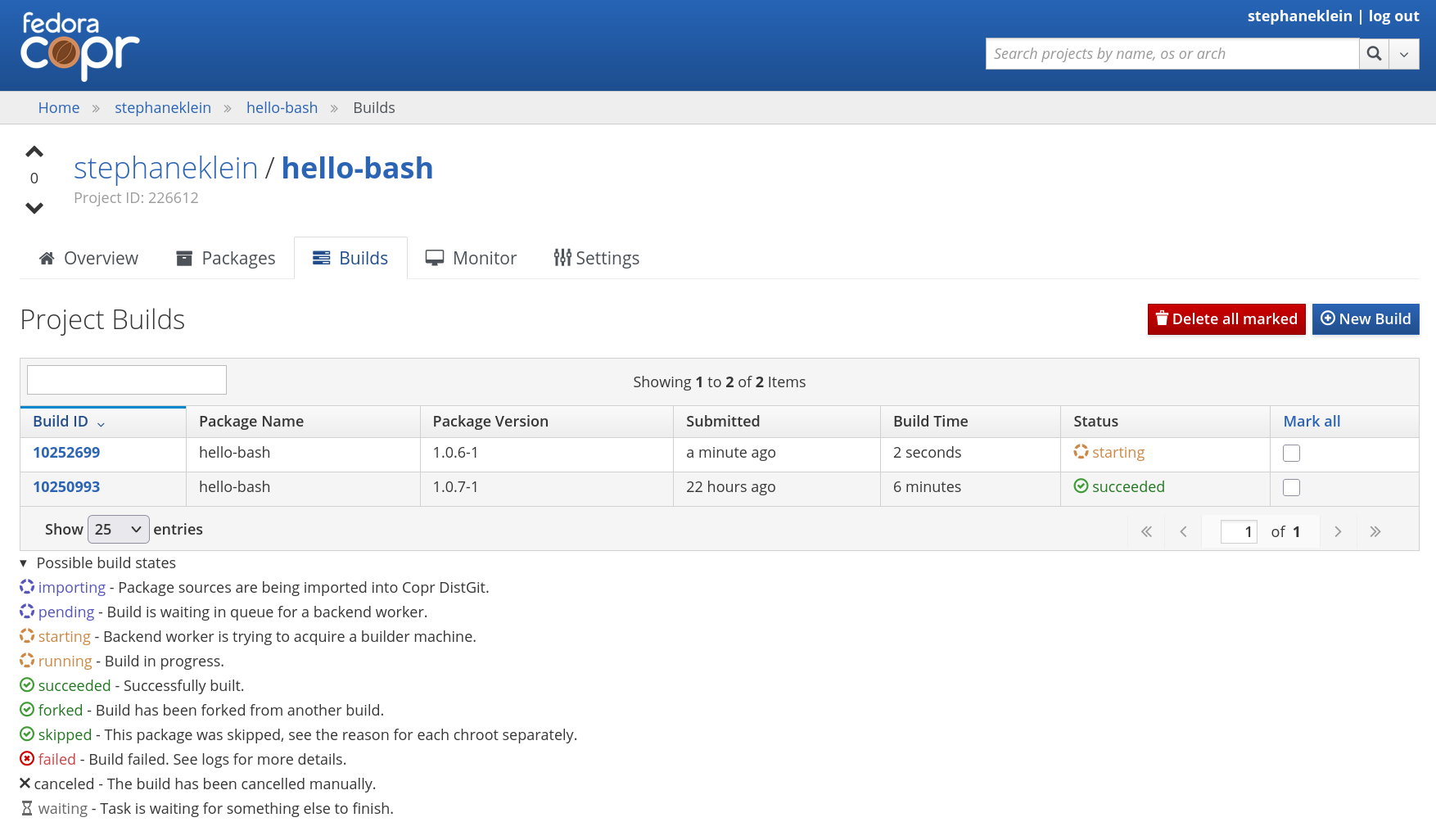
Une fois le build des packages terminé, il est facile d'installer le package avec les commandes suivantes :
$ sudo dnf copr enable -y stephaneklein/hello-bash
$ sudo dnf install -y hello-bash
$ hello-bash
Hello World
Automatisation GitOps avec COPR
Et pour finir, j'ai implémenté dans le playground l'automatisation complète de la compilation et publication des packages sur l'infrastructure COPR.
Pour cela, dans le script init-copr-project.sh j'ai déclaré l'URL du repository qui contient le code source :
...
copr-cli add-package-scm "$COPR_PROJECT" \
--name hello-bash \
--clone-url https://github.com/stephane-klein/fedora-rpm-copr-playground.git \
--commit bash \
--subdir . \
--spec rpm/hello-bash.spec \
--type git \
--method make_srpm \
--webhook-rebuild on
Le paramètre --commit bash permet de définir la branche Git à utiliser comme source.
Le paramètre --method make_srpm, qui permet à l'utilisateur d'utiliser un script personnalisé de génération du SRPM, à placer dans /.copr/Makefile à la racine du dépôt avec une cible srpm, exemple :
specfile = rpm/hello-bash.spec
.PHONY: srpm
srpm: $(specfile)
mkdir -p /tmp/copr-srpm-build
cp rpm/hello-bash.spec /tmp/copr-srpm-build/hello-bash.spec
cp -r . /tmp/copr-srpm-build/source/
cd /tmp/copr-srpm-build && \
rpmbuild -bs hello-bash.spec \
--define "_topdir /tmp/copr-srpm-build/rpmbuild" \
--define "dist .fc42" \
--define "_sourcedir /tmp/copr-srpm-build/source"
cp /tmp/copr-srpm-build/rpmbuild/SRPMS/*.src.rpm $(outdir)
Je ne souhaite pas détailler ici d'autres méthodes comme tito ou Packit, mais la méthode make_srpm est la plus flexible, elle permet de contrôler entièrement comment le SRPM est construit.
Une fois tout ceci configuré, il est possible de rebuild le package directement en cliquant sur le bouton "Rebuild" sur l'interface web de COPR :
Dernière étape : j'ai implémenté un build automatique qui est déclenchée par un appel curl dans le job GitHub Actions /.github/workflows/trigger-copr-build.yml, dont voici le contenu :
name: Trigger Copr Build
on:
push:
tags:
- '*'
jobs:
trigger-copr-build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Verify tag is on bash branch
run: |
if ! git branch -r --contains ${{ github.ref_name }} | grep -q "origin/bash"; then
echo "Tag ${{ github.ref_name }} is not on branch bash"
exit 1
fi
- name: Trigger Copr webhook
run: |
curl -X POST https://copr.fedorainfracloud.org/webhooks/custom/226325/3cf20247-820b-4050-bfb1-593b01a6996f/hello-bash/
Ce job est exécuté à chaque publication d'un nouveau Git tag, suivi d'une vérification que le tag provient bien de la branche bash.
Claude Sonnet 4.6 m'a suggéré l'existence d'une méthode de polling de dépôt Git intégrée à COPR, mais je n'ai trouvé aucune trace de celle-ci dans la documentation.
J'ai aussi essayé d'utiliser la méthode basée sur les webhooks GitHub de COPR, mais je n'ai pas réussi à la faire fonctionner. L'interface de GitHub m'indiquait à chaque fois une erreur dans la réponse des calls HTTP. C'est pour cela que j'ai fini par déclencher le webhook custom via un job GitHub Actions.
Package d'un projet en Golang
Le playground contient aussi le packaging d'une application en Golang, consultable dans la branche golang.
Voici le contenu du fichier /golang/rpm/hello-golang.spec :
Name: hello-golang
Version: 1.0.10
Release: 1%{?dist}
Summary: A simple Hello World Go application
License: MIT
URL: https://github.com/stephane-klein/fedora-rpm-copr-playground
Source0: %{name}-%{version}.tar.gz
BuildRequires: golang >= 1.21
%description
A simple "Hello World" Go application packaged as an RPM for Fedora COPR.
%prep
%autosetup
%build
go build -ldflags "-X main.version=%{version}" -o %{name}
%install
mkdir -p %{buildroot}%{_bindir}
cp %{name} %{buildroot}%{_bindir}/
%files
%{_bindir}/%{name}
%changelog
* Fri Mar 20 2026 Stéphane Klein <contact@stephane-klein.info> - 1.0.0-1
- Initial release
Les principales différences avec la version pour Bash :
- Absence de
BuildArch: noarch - Présence de
BuildRequires: golang >= 1.21 - Et l'ajout des instructions suivantes :
%prep
%autosetup
%build
go build -ldflags "-X main.version=%{version}" -o %{name}
Peu de changement au niveau du script /build-rpm-locally.sh, qui génère ces fichiers :
rpmbuild
├── BUILD
├── RPMS
│ └── x86_64
│ ├── hello-golang-1.0.10-1.fc42.x86_64.rpm
│ ├── hello-golang-debuginfo-1.0.10-1.fc42.x86_64.rpm
│ └── hello-golang-debugsource-1.0.10-1.fc42.x86_64.rpm
├── SOURCES
│ ├── hello-golang-1.0.10
│ │ ├── go.mod
│ │ └── main.go
│ └── hello-golang-1.0.10.tar.gz
├── SPECS
└── SRPMS
└── hello-golang-1.0.10-1.fc42.src.rpm
Cette fois, plus rien dans le dossier RPMS/noarch/, la commande rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-golang.spec build le package pour la distribution de la workstation du développeur.
Pour le reste, je n'ai pas identifié de différence majeure entre la version Bash et la version Golang
La suite… méthode Tito et Packit
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour stephane-klein/fedora-rpm-copr-playground pour les tester et ensuite publier une nouvelle note de compte rendu.
Je découvre l'offre "Go" de OpenCode, « Go - Modèles de code à faible coût pour tous », qui semble être sortie le 25 février 2026 : https://xcancel.com/opencode/status/2026553685468135886.
Je n'ai rien trouvé à ce sujet sur Hacker News ni chez Simon Willison.
D'après ce que je comprends, alors que l'offre OpenCode Zen propose un point d'accès et une facturation unifiés du type Pay-As-You-Go, comme OpenRouter, OpenCode Go est une offre d'abonnement à 10 dollars par mois, selon les mêmes principes que les plans d'abonnement comme Anthropic Claude Pro, Max, etc.
L'offre OpenCode Go propose un accès uniquement à 3 LLMs, tous Open Weights et tous chinois : GLM-5, Kimi K2.5 et MiniMax M2.5.
À noter toutefois que OpenCode Go n'utilise aucun AI provider basé en Chine :
Privacy : The plan is designed primarily for international users, with models hosted in the US, EU, and Singapore for stable global access.
Contrairement à Anthropic (voir Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?), OpenCode semble être transparent sur leur offre :
Usage limits
OpenCode Go includes the following limits:
- 5 hour limit — $12 of usage
- Weekly limit — $30 of usage
- Monthly limit — $60 of usage
Limits are defined in dollar value. This means your actual request count depends on the model you use. Cheaper models like MiniMax M2.5 allow for more requests, while higher-cost models like GLM-5 allow for fewer.
The table below provides an estimated request count based on typical Go usage patterns:
GLM-5 Kimi K2.5 MiniMax M2.5 requests per 5 hour 1,150 1,850 20,000 requests per week 2,880 4,630 50,000 requests per month 5,750 9,250 100,000 Estimates are based on observed average request patterns:
- GLM-5 — 700 input, 52,000 cached, 150 output tokens per request
- Kimi K2.5 — 870 input, 55,000 cached, 200 output tokens per request
- MiniMax M2.5 — 300 input, 55,000 cached, 125 output tokens per request
You can track your current usage in the console.
Comparaison des prix au million de tokens des plans Claude Max et OpenCode Go
Si je pars des prix listés sur l'offre OpenCode Zen et les prix de Sonnet 4.6 chez Anthropic, je peux dresser le tableau suivant, prix exprimé en millions de tokens :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 | $0.30 | $1.20 | $0.06 | $0.375 |
| GLM 5 | $1.00 | $3.20 | $0.20 | - |
| Kimi K2.5 | $0.60 | $3.00 | $0.10 | - |
| Sonnet 4.6 | $3.00 | $15.00 | $0.30 | $3.75 |
Ensuite, j'ajuste ces prix avec les réductions offertes :
- par le plan Claude Max à $100 / mois, soit une réduction de 92,56 % (
(1345 - 100) / 1345 × 100 = 92,56 %) - par OpenCode Go, soit une réduction de 83,33 % (
(60 - 10) / 60 × 100 = 83,33 %)
Cela donne :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 (avec offre Go) | $0.05 | $0.20 | $0.01 | $0.06 |
| GLM 5 (avec offre Go) | $0.16 | $0.53 | $0.03 | - |
| Kimi K2.5 (avec offre Go) | $0.10 | $0.50 | $0.01 | - |
| Sonnet 4.6 (avec offre Max) | $0.22 | $1.11 | $0.02 | $0.27 |
Sur la base du leaderboard SWE-bench Verified, je vais partir des hypothèses suivantes :
- Si je considère arbitrairement que GLM-5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est légèrement moins cher que l'offre Claude Max
- Si je considère arbitrairement que Kimi K2.5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est deux fois moins cher que l'offre Claude Max
#JaiDécidé de tester l'offre OpenCode Go sur un projet d'outil d'archivage à froid de conversations Mattermost en Golang que je coderai from scratch. Je compte réaliser deux versions de ce projet en parallèle : une version avec Sonnet 4.6 et l'autre avec les modèles de OpenCode Go.
Journal du jeudi 12 mars 2026 à 11:18
En étudiant l'offre OpenCode Go, je suis tombé sur une page marketing du service ApiYi : « Is the OpenCode GO Plan Worth Buying? $10/Month 3 Model Tests + 5 Major Alternative Solutions Compared ».
En analysant le contenu avec Sonnet 4.6, j'ai compris qu'ApiYi fonctionne vraisemblablement comme une solution de contournement à destination du marché chinois : les utilisateurs qui ne peuvent pas acheter directement auprès d'Anthropic — en raison des risques de bannissement liés aux adresses IP et aux moyens de paiement chinois — y trouvent un accès indirect aux modèles.
Journal du jeudi 12 mars 2026 à 00:51
J'ai regroupé dans cette note les feedbacks que j'ai reçus à propos de ma note « Ma cartographie de l'écosystème LLM de 2026 ». En principe, je considère que mes notes éphémères sont immuables, mais je vais cette fois me permettre d'y apporter quelques corrections et d'en tracer les changements dans la présente note.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs connectent leurs applications aux LLMs en passant par une Web API qui respecte généralement la convention OpenAI Chat Completions compatible API.
Un ami m'a dit : « Plus personne ne fait de "completion", on migre tous vers la Responses API. »
Jusqu'à présent, je ne m'étais jamais vraiment penché sur les spécifications d'API des AI providers. Je m'étais contenté d'utiliser des bibliothèques IA et des AI Frameworks, en supposant naïvement qu'des outils comme Aider, llm (cli), Open WebUI ou OpenCode s'appuyaient tous sur l'OpenAI Chat Completions compatible API, et que les nouvelles fonctionnalités — tools, prompt caching, etc. — s'intégraient simplement via de nouveaux champs dans le JSON. Après analyse, ce n'est pas le cas.
L'API "completions" est d'ailleurs désormais classée dans la section « Legacy » de la documentation d'OpenAI, et OpenAI cherche à imposer un nouveau standard avec Open Responses.
La lecture de l'article OpenAI Responses API vs. Chat Completions vs. Messages API confirme que trois formats d'API dominent aujourd'hui :
Today, three API formats dominate how AI Agents talk to LLMs:
- OpenAI's Chat Completions API — the de facto standard, universally supported
- OpenAI's Responses API — the newer, agent-oriented evolution with built-in tools and state management
- Anthropic's Messages API — Claude's native interface, with capabilities like extended thinking and prompt caching
Mistral AI, de son côté, semble encore s'appuyer sur l'OpenAI Chat Completions compatible API : son endpoint reste POST /v1/chat/completions.
Je comprends mieux maintenant, pourquoi des frameworks comme l'AI SDK proposent une implémentation par provider : chaque API diverge suffisamment pour nécessiter un adaptateur dédié 😯.
Je constate que OpenRouter proposes les trois API :
POST https://openrouter.ai/api/v1/chat/completions(lien vers la documentation)POST https://openrouter.ai/api/v1/responses(lien vers la documentation)POST https://openrouter.ai/api/v1/messages(lien vers la documentation)
C'est là l'un des intérêts d'OpenRouter : une abstraction unifiée au-dessus d'une multitude d'AI providers.
Voici la nouvelle version de mon paragraphe :
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Mon ami m'a aussi fait remarquer :
« Tu utilises interchangeablement "LLM" et "le produit". Dans "De nombreux LLMs permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes", c'est pas le LLM lui-même, c'est le wrapper autour qui fait ça — le LLM s'en fiche. »
J'avais en effet manqué de rigueur à plusieurs endroits ; j'ai corrigé ma note.
Autre retour :
Dans ton histoire de middle tu peux aussi parler de prompt répétition : Prompt Repetition Improves Non-Reasoning LLMs.
Je ne connaissais pas cette astuce. J'ai ajouté cette phrase dans ma note :
« Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour. »
Autre retour :
« Tes notes sur le prompt caching pourraient être plus précises. C'est utile pour plus de cas, mais il ne faut pas vraiment y penser comme à un cache software. »
En effet, je vois un autre usage évident : une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur.
J'ai ajouté ce paragraphe à ma note :
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
J'ai reçu le retour suivant d'une autre personne :
Je crois qu'en plus d'utiliser des Inferences Engines les AIs providers utilisent aussi des Workload Managers, Mistral avait mis https://github.com/SchedMD/slurm dans ses offres d'emploi compute
D'après ce que j'ai compris, Slurm Workload Manager est un projet qui a commencé en 2002, généralement utilisé sur des clusters High-performance computing (HPC) pour lancer de gros traitements de calcul, qui peuvent durer plusieurs heures ou même des jours, sur du matériel mutualisé entre plusieurs laboratoires de recherche.
J'ai trouvé cette mention dans une offre d'emploi qui semble aller dans le sens de cette hypothèse :
Now, it would be ideal if you also had:
• Experience with HPC workload managers (Slurm) and distributed storage systems (Lustre, Ceph)
Je pense que Mistral AI utilise Slurm pour leur offre Compute - built infrastructure for AI builders, qui permet à leurs clients de créer ou de fine-tuner des modèles.
Je ne pense pas que Slurm soit utilisé pour leur offre AI provider : c'est un ordonnanceur batch conçu pour des jobs longs et prévisibles, alors que l'inférence requiert une faible latence et la capacité à traiter des requêtes à la volée — deux patterns fondamentalement différents. Par conséquent, je n'ai pas inclus ce sujet dans ma cartographie de l'écosystème LLM de 2026.
Une troisième personne m'a fait des retours :
Il y un concept important que tu ne cites pas, c'est l'embedding (vectorisation).
En effet, j'ai oublié d'en parler. Je viens d'ajouter le paragraphe suivant dans ma note :
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Cette même personne m'a aussi partagé :
je suis dans une phase d'exploration du Specs Driven Development.
Je connais la méthode, bien que je n'aie jamais remarqué qu'elle portait un nom : Specs Driven Development (SDD). Je pense que j'ai plus ou moins suivi cette méthode dans le fichier AGENTS.md de mon projet qemu-compose.
Je prépare très souvent mes specs quand je suis dans le métro ou quand je marche. Je réalise que mes notes publiques de projets me sont de plus en plus utiles comme base de spécification à soumettre aux LLMs, comme par exemple celle-ci : Première description du gestionnaire de projet de mes rêves.
J'ai fait quelques recherches sur le sujet du Specs Driven Development et je suis tombé sur le thread Hacker News « Spec-Driven Development: The Waterfall Strikes Back » ainsi que sur la section « Do you do spec-driven development? » d'un billet de blog. La pratique ne semble pas faire consensus. Je n'ai pas encore d'avis tranché sur la question.
Au passage, j'ai découvert ici deux autres noms de concepts : Verified Spec-Driven Development (VSDD) et Verification-Driven Development (VDD).
Je n'ai pas ajouté ces informations dans ma note de cartographie.
En rédigeant cette note, je me suis rendu compte que j'avais oublié quelques sujets.
J'ai ajouté un paragraphe sur le reranking :
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence.- Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
J'ai aussi ajouté un paragraphe sur chain-of-thought (CoT) :
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètreeffort.
Les modèles Claude Sonnet et Opus4.xadaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
Et pour finir, j'ai ajouté un paragraphe à propos des API de type "Batch" :
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples :
POST /v1/messages/batchespour Anthropic,POST /batchespour OpenAI, ouPOST /v1/batch/jobspour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard. Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Serveur MCP web fetch local sous Claude Desktop pour contourner les blocages IP de certains sites
Mon installation de Claude Desktop sous Fedora était principalement motivée par l'exécution locale du tool "Web fetch tool" d'Anthropic, afin de contourner le blocage des IP d'Anthropic par certains sites web.
Après avoir passé en revue une demi-douzaine de serveurs MCP de type « web fetch », j'ai retenu zcaceres/fetch-mcp, implémenté en Javascript, qui, après quelques heures d'utilisation, semble bien fonctionner.
Voici mon fichier ~/.config/Claude/claude_desktop_config.json après configuration du serveur MCP :
{
"mcpServers": {
"fetch": {
"command": "npx",
"args": ["mcp-fetch-server"],
"env": {
"DEFAULT_LIMIT": "0"
}
}
},
"isUsingBuiltInNodeForMcp": false,
"isDxtAutoUpdatesEnabled": false,
"preferences": {
"coworkScheduledTasksEnabled": true,
"ccdScheduledTasksEnabled": true,
"coworkWebSearchEnabled": true,
"sidebarMode": "chat"
}
}
zcaceres/fetch-mcp supporte différents types de formats de fetching :
All tools accept the following common parameters:
- fetch_html — Fetch a website and return its raw HTML content.
- fetch_markdown — Fetch a website and return its content converted to Markdown.
- fetch_txt — Fetch a website and return plain text with HTML tags, scripts, and styles removed.
- fetch_json — Fetch a URL and return the JSON response.
- fetch_readable — Fetch a website and extract the main article content using Mozilla Readability, returned as Markdown. Strips navigation, ads, and boilerplate. Ideal for articles and blog posts.
- fetch_youtube_transcript — Fetch a YouTube video's captions/transcript. Uses
yt-dlpif available, otherwise extracts directly from the page. Accepts an additionallangparameter (default:"en") to select the caption language.
C'est le LLM qui choisit quel tool utiliser. J'ai demandé à Claude Sonnet 4.6 comment il effectuait son choix : par défaut, il utilise fetch_markdown ; lorsqu'il sait qu'un site contient des publicités, une sidebar, etc. — généralement les sites de presse —, il utilise fetch_readable.
J'ai observé que les tools fetch_markdown, fetch_readable et fetch_json fonctionnent bien, mais fetch_youtube_transcript n'a pas fonctionné chez moi. D'après les logs, ce tool semble contenir un bug. #JaimeraisUnJour essayer de le corriger.
Ma cartographie de l'écosystème LLM de mars 2026
Dans cette hub note, j'essaie de cartographier les principaux concepts et composants de l'écosystème LLM, d'en clarifier les relations et d'affiner mon vocabulaire. Les dates et la dimension historique sont volontairement absentes — cette note décrit l'écosystème tel qu'il est en 2026, pas comment il en est arrivé là.
À la base, on trouve les laboratoires de recherche — OpenAI, Anthropic, Mistral AI, DeepSeek, Qwen Team, etc. — qui entraînent et publient les modèles. Ces modèles sont ensuite instanciés par des AI providers — Vertex AI (Google), Bedrock (AWS), Scaleway Generative APIs, chutes.ai, etc — qui les rendent accessibles via une API. La plupart des LLM producers jouent également ce rôle d'AI provider pour leurs propres modèles.
OpenRouter est également un AI provider, mais d'un type particulier : c'est un proxy qui s'intercale devant de nombreux AI providers pour offrir un point d'accès et une facturation unifiés.
Les AI providers instancient des Inference Engines — llama.cpp, vLLM, SGLang, ExLlamaV2, etc. — sur leurs serveurs, en y chargeant les poids d'un LLM.
Ces serveurs coûtent très cher, environ 30 000 € pour des H200, 40 000 € pour des B200, 50 000 € pour des B300. Les GPU de ces serveurs sont gravés par TSMC, tandis que la mémoire HBM est produite principalement par SK Hynix.
Si je simplifie, il existe deux familles de LLM, les modèles denses et les modèles Mixture of Experts (MoE). Ces derniers permettent un coût d'inférence réduit à paramètres totaux équivalents.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Beaucoup d'AI providers proposent deux modes de facturation : un abonnement donnant accès à leur agent conversationnel web, et un mode Pay-As-You-Go (à l'usage) donnant accès à leur Web API.
Le texte saisi par l'utilisateur dans un agent conversationnel web est transmis à l'API de l'AI provider au sein d'un prompt, qui contient également le System Prompt (LLM), l'historique de la conversation, et éventuellement du contexte additionnel. La taille maximale de l'ensemble prompt et réponse est nommée context window, exprimée en tokens.
Lorsque l'application enrichit ce prompt avec des données externes — issues d'une base de données vectorielle, d'une base de données relationnelle, d'un moteur de recherche full-text ou d'un moteur de recherche web — on nomme cette technique : RAG (Retrieval-Augmented Generation).
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual, Voyage AI Text Embeddings ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence. - Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
Beaucoup de LLMs ont tendance à moins bien utiliser les informations situées au milieu d'un très long contexte — ce problème est nommé lost in the middle. Cela pénalise notamment les RAG, dont les chunks pertinents injectés en milieu de contexte risquent d'être sous-exploités par le modèle. Certains LLMs modernes comme Gemini 2.5 Pro ou GLM-5 ne sont plus victimes du lost in the middle sur de longs contextes. Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour.
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue
depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètre effort.
Les modèles Claude Sonnet et Opus 4.x adaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
De nombreux AI provider permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes. Un tool est décrit sous la forme d'une structure JSON, constituée des champs name, description, input_schema. En fonction du contenu des messages, le LLM peut prendre la décision de demander l'exécution d'un ou plusieurs tools. Cette demande se matérialise dans le JSON de sa réponse (voir exemple).
Il existe deux types de tools :
- des built-in tools, fournis et exécutés par le AI provider — Web search, Web fetch, Code execution, Memory, etc.
- des custom tools, définis par le développeur via le Function calling, dont l'exécution est prise en charge par l'application.
La facturation des built-in tools est généralement incluse dans les abonnements des AI providers. Par contre, elles sont généralement facturées individuellement dans l'offre Pay-As-You-Go.
La majorité des AI providers supportent le standard Structured Outputs d'OpenAI pour garantir une réponse conforme à un JSON Schema précis.
Anthropic, quant à lui, ne supporte pas ce standard mais permet tout de même la génération de réponses structurées en JSON en passant par un tool.
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise. En poussant l'idée, on peut dire qu'un assistant IA conversationnel basique, sans tools ni boucle, est la forme la plus minimaliste d'un AI agent. Les assistants conversationnels modernes comme ChatGPT ou Claude sont quant à eux devenus de véritables agents à part entière.
Les Inference Engines sont par nature stateless — chaque requête est traitée de façon indépendante, sans mémoire des échanges précédents. Certains AI providers proposent néanmoins du prompt caching : lorsqu'une portion du prompt est identique d'une requête à l'autre — même ordre, même contenu, token pour token — elle est mise en cache pour une courte durée, ce qui réduit à la fois la latence et le coût. C'est particulièrement utile pour les AI coding agents, dont les longues boucles agentiques répètent à chaque étape le même system prompt et le même historique de conversation.
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples : POST /v1/messages/batches pour Anthropic, POST /batches pour OpenAI, ou POST /v1/batch/jobs pour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard.
Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Le protocole MCP standardise la définition, la découverte et l'exécution de tools exposés par des serveurs externes.
Cela permet de connecter un AI agent à des centaines de serveurs MCP sans avoir à écrire la moindre ligne de code.
Cela permet aussi à n'importe quel développeur de publier un serveur MCP pour rendre son service accessible aux AI agents.
La logique est proche des API REST, à la différence que les interfaces MCP sont conçues pour être utilisées par des AI agents plutôt que par des développeurs.
Les AI agents devenant de plus en plus complexes à orchestrer, les développeurs s'appuient sur des frameworks agentiques — Vercel AI SDK, LangGraph, VoltAgent, etc. — pour gérer les boucles, la mémoire, les tools et l'observabilité.
Les développeurs utilisent des AI coding agents dans des agentic coding tools comme Claude Code, OpenCode, etc. Ces agents utilisent massivement les tools et chargent du contexte projet depuis des fichiers AGENTS.md — un standard collaboratif initié par Sourcegraph, OpenAI et Google.
Les AI coding agents peuvent également charger dynamiquement des « compétences » depuis des fichiers SKILL.md, un format introduit par Anthropic.
Lorsqu'il utilise un agentic coding tool comme Claude Code ou OpenCode, le développeur peut choisir quel type d'AI coding agent utiliser selon la nature de la tâche — certains moins coûteux pour les tâches simples, d'autres plus capables pour les tâches complexes. Par exemple pour OpenCode on trouve : agent build, agent plan, agent general, agent explore. Chez Claude Code : agent explore, agent plan, agent general-purpose. Ces agents peuvent également travailler en essaim : un agent orchestrateur décompose le travail et délègue des sous-tâches à plusieurs sous-agents exécutés en parallèle.
Certains agents conversationnels web, comme ChatGPT, Claude, etc., proposent des fonctionnalités de "memory layers" basées sur des tools spécifiques. Ces implémentations restent à ce jour plus opaques et moins puissantes que les services dédiés comme mem0, Graphiti, Letta, etc.
Les services de couche mémoire persistante utilisent généralement une architecture hybride combinant une base de données vectorielle et une base de données de graphe : la base vectorielle stocke des informations sémantiques probabilistes et le graphe stocke des informations symboliques. Ces deux types de données permettent de fournir à un agent IA un meilleur contexte.
Les développeurs peuvent tester leurs prompts et leurs AI agents avec des outils d'évaluation, comme Promptfoo, trulens, etc. Ces outils sont nommés LLM Evals ou harnais (harness). Cela ressemble un peu à des tests unitaires, mais à la différence de ces derniers, qui sont déterministes, les LLM Evals évaluent la qualité des réponses des LLMs de manière probabiliste, généralement en utilisant un LLM-as-a-Judge.
Des laboratoires de recherche en AI privés — OpenAI avec SimpleQA et PaperBench, Google DeepMind avec IFEval et FACTS Grounding, etc. — ou académiques (UC Berkeley avec Chatbot Arena, Princeton avec SWE-bench, Center for AI Safety avec GPQA et HLE) et des communautés (EleutherAI avec le LM Evaluation Harness, Hugging Face avec l'Open LLM Leaderboard) mettent au point des benchmarks pour publier des leaderboards publics. Les créateurs de LLM disposent également de benchmarks internes privés, dont les méthodologies et résultats ne sont pas communiqués de manière transparente.
2026-03-12 : des petites erreurs ont été corrigées et j'ai ajouté 7 paragraphes (détail des changements).
J'ai découvert le modèle Open Weights GLM-5
#JaiDécouvert le modèle GLM-5 Open Weights de la société chinoise Z.ai : https://glm5.net
- Note de Simon Willison : https://simonwillison.net/2026/Feb/11/glm-5/
- Thread Hacker News : GLM-5: Targeting complex systems engineering and long-horizon agentic tasks
Analyse de Sonnet 4.6 des commentaires :
En se basant sur les retours concrets du fil, GLM-5 impressionne pour le coding agentique : cmrdporcupine rapporte un refactoring réussi dans un langage propriétaire pour seulement $1.50, avec une analyse initiale meilleure que GPT 5.3. Plusieurs utilisateurs le positionnent au niveau d'Opus 4.5 voire au-delà pour les tâches bien définies, à une fraction du coût. Le plan coding de Z.ai est cité comme une alternative crédible aux abonnements Anthropic, dont les limites d'usage dégradées poussent beaucoup à chercher ailleurs. Le scepticisme subsiste néanmoins sur le benchmaxxing — les comparaisons publiées portent sur Opus 4.5 et non sur Opus 4.6, la dernière génération.
Je constate que GLM-5 est mentionné / conseillé dans le README.md de Oh My OpenCode :
Even only with following subscriptions, ultrawork will work well (this project is not affiliated, this is just personal recommendation):
- ChatGPT Subscription ($20)
- Kimi Code Subscription ($0.99) (*only this month)
- GLM Coding Plan ($10)
- If you are eligible for pay-per-token, using kimi and gemini models won't cost you that much.
et
- Sisyphus (
claude-opus-4-6/kimi-k2.5/glm-5) is your main orchestrator. He plans, delegates to specialists, and drives tasks to completion with aggressive parallel execution. He does not stop halfway.- Hephaestus (
gpt-5.3-codex) is your autonomous deep worker. Give him a goal, not a recipe. He explores the codebase, researches patterns, and executes end-to-end without hand-holding. The Legitimate Craftsman.- Prometheus (
claude-opus-4-6/kimi-k2.5/glm-5) is your strategic planner. Interview mode: it questions, identifies scope, and builds a detailed plan before a single line of code is touched.
J'observe que GLM-5 est plutôt bien placé dans les leaderboard SWE-bench :
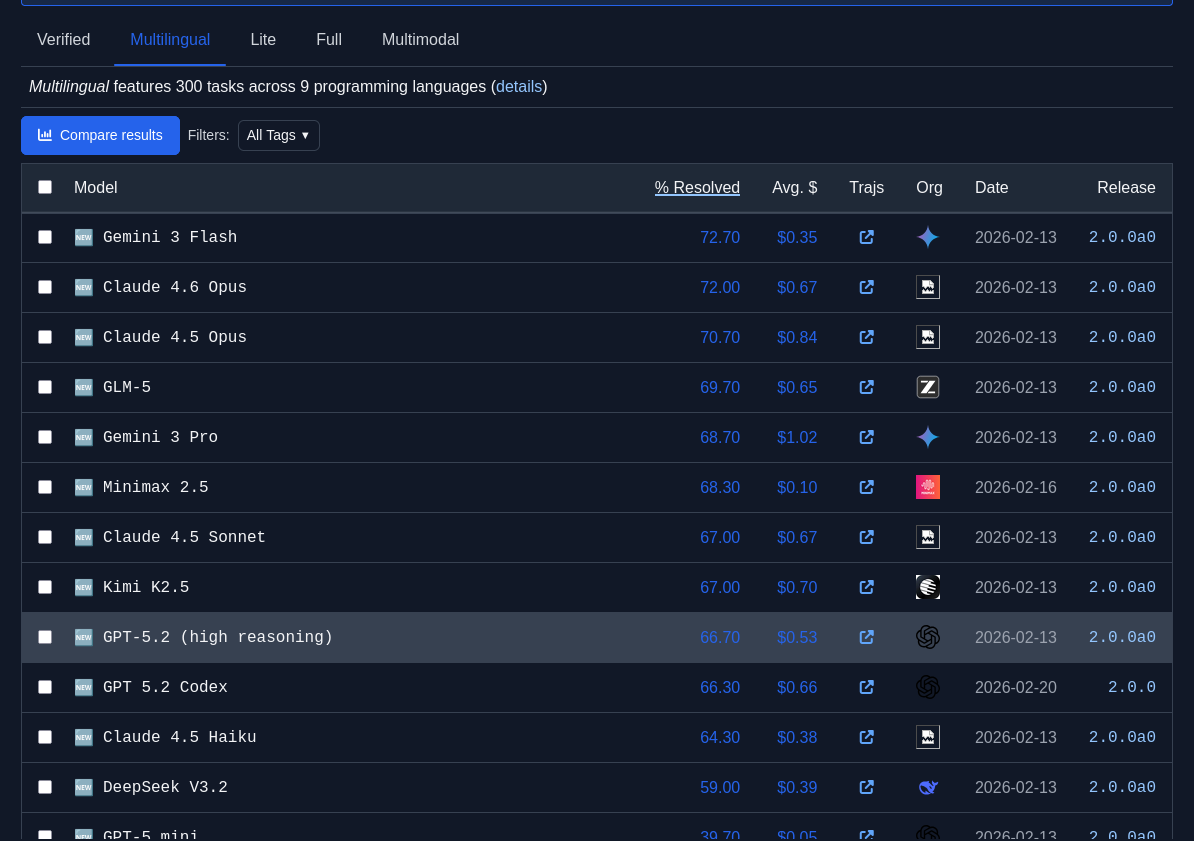
Je constate que GLM-5 est meilleur que Devstral 2 (Mistral) qui a un score de 61.3%.
J'ai découvert Promptfoo qui permet de faire du LLM Eval
Cette note a été partiellement écrite fin novembre 2025 et publiée 3 mois plus tard, fin février 2026.
Souhaitant améliorer mes prompts et combler mes lacunes en prompt engineering, je me suis mis à chercher des outils permettant de pratiquer quelque chose qui ressemblerait au Test driven development appliqué à la conception de prompts.
Via Claude Sonnet 4.5, #JaiDécouvert Promptfoo (https://github.com/promptfoo/promptfoo), un framework Javascript permettant notamment de faire du LLM Eval.
Cela fait plusieurs mois que je croise l'expression LLM Eval, sans avoir jamais pris le temps de comprendre ce que ce concept signifie précisément.
D'après ce que j'ai compris, la différence essentielle entre Unit testing et LLM Eval, c'est que les tests unitaires sont déterministes, alors que la qualité des réponses des LLM est évaluée de manière probabiliste.
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.